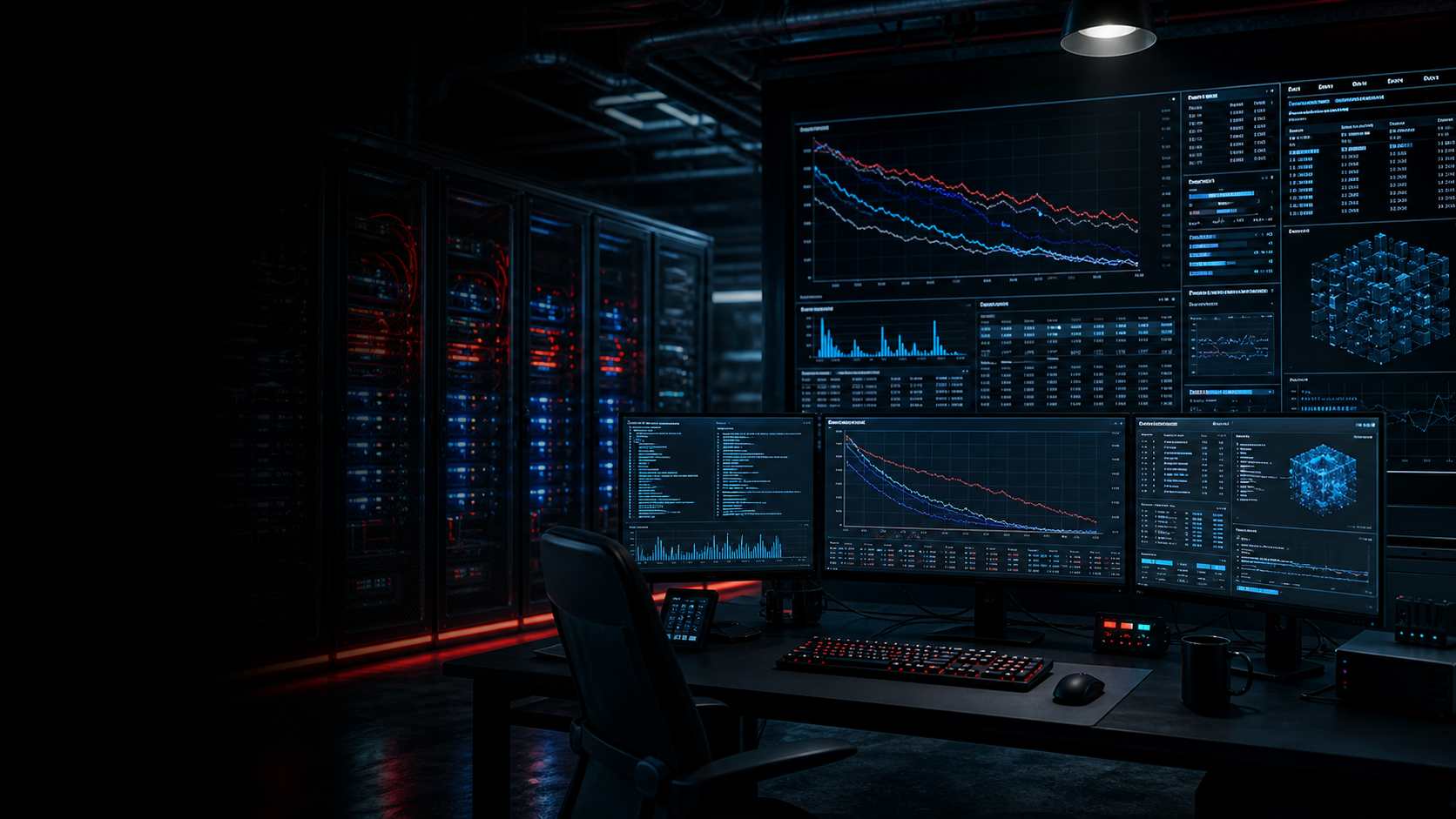
01 / dane
Korpus, licencje, jakość
Na sesjach budujemy dataset, usuwamy śmieci, deduplikujemy, odcinamy benchmark contamination i zapisujemy provenance.
To nie jest kurs wideo. To warsztatowa społeczność na Discordzie, w której spotykamy się 2-3 razy w tygodniu, robimy zadania jak na ćwiczeniach na uniwersytecie i uczymy się treningu modeli przez realne uruchamianie pipeline'u.
Slayer jest dla osób technicznych, które chcą zrozumieć, co dzieje się pod spodem. Mamy plan, slajdy i repozytoria, ale materiał nie jest produktem samym w sobie. Produktem jest praca w grupie: sesje, zadania, review i decyzje treningowe.
Na sesjach budujemy dataset, usuwamy śmieci, deduplikujemy, odcinamy benchmark contamination i zapisujemy provenance.
Wspólnie trenujemy tokenizer, mierzymy kompresję na polskich danych i sprawdzamy, kiedy vocabulary niszczy koszt treningu.
Przechodzimy przez blok transformera, attention, MLP, normy, embeddingi i rope tak, żeby umieć debugować training run.
Robimy batching, optimizer, scheduler, mixed precision, gradient clipping, checkpointing i czytamy realne logi z loss curve.
Projektujemy proxy benchmark, sanity checki generacji, regresje i metryki, które zatrzymują słaby run przed spaleniem GPU.
Przerabiamy eksport, kwantyzację, vLLM/llama.cpp, OpenAI-compatible endpoint i podstawy monitoringu kosztu tokenów.
Krótkie sesje robocze: kontekst, decyzja techniczna, live coding albo review, potem konkretne zadanie do wykonania.
Wrzucamy logi, configi, wykresy, sample i błędy. Grupa widzi, co nie działa, i uczy się na realnych awariach.
Repozytoria są punktem startowym, nie gotową odpowiedzią. Uczestnicy dopisują pipeline, uruchamiają runy i porównują wyniki.
Slajdy porządkują pojęcia, ale nie zastępują pracy. Najważniejsze rzeczy dzieją się podczas sesji i po nich.
Finałem nie jest obejrzany materiał. Finałem jest własne repo, logi, checkpoint, benchmark i intuicja, która powstaje dopiero wtedy, gdy samemu naprawia się training run.
Wspólnie opracowana lista źródeł, filtry, licencje, deduplikacja, holdout i audit trail danych.
Porównanie tokenizacji, kompresji i kosztu z wynikami omawianymi na sesjach.
Konfiguracja, krzywa loss, checkpointy, sample, awarie i decyzje omawiane na Discordzie.
Minimalny prywatny benchmark, sanity checks, scoring i bramki przed kolejnym kosztem GPU.
Zapisy i szczegóły kohorty przez email. Kontakt: k.wikiel@gmail.com.
Ta strona nie umożliwia zakupu ani płatności. Wysłanie e-maila jest wyłącznie zapytaniem i nie zawiera umowy. Przed ewentualnym zakupem otrzymasz cenę łączną, zakres i czas dostępu, wymagane informacje konsumenckie, regulamin oraz potwierdzenie warunków na trwałym nośniku.